目录
Redis
Day01
一、Redis的基本概念
1、关系型数据库与非关系型数据库
关系型数据库:MySQL就是典型的关系型数据库,使用表结构。
非关系型数据库:redis是典型的非关系型数据库,存放数据的时候,使用键值对的形式。
2、非关系型数据库的分类
基于键值对 key-value类型:Redis,memcached 列存储数据库 Column-oriented Graph:HBase 图形数据库 Graphs based:Neo4j 文档型数据库: MongoDB,MongoDB是一个基于分布式文件存储的数据库,主要用来处理大量的文档。
3、redis的基本概念
远程字典服务器。使用C语言进行编写的,开源的,性能比较高。主要用作数据库、缓存和消息中间件,是基于内存运行的,并且支持持久化。
redis中文官网:http://www.redis.cn/( redis英文官网:https://redis.io/
4、redis的特性
- 支持持久化
- 支持丰富的数据类型,例如:string、list、set、sort set、hash
- 支持数据的备份,主从复制
5、redis的优点
- 性能极高 每秒钟可以读11w次,每秒钟可以写8.1w次
- 支持丰富的数据类型
- 原子性
- 丰富的特性 发布订阅、key过期。
二、Redis基本命令
展开代码#数据库的切换 select + index #清空当前数据库 flushdb #清空所有数据库 flushall #查看当前数据库的大小 dbsize #查看当前数据库有哪些key值 keys *、keys k? #删除某个key del key #设置key的过期时间 expire key seconds #查看key的过期时间 ttl key #-1表示永不过期,-2表示已过期 #查看key的类型 type key
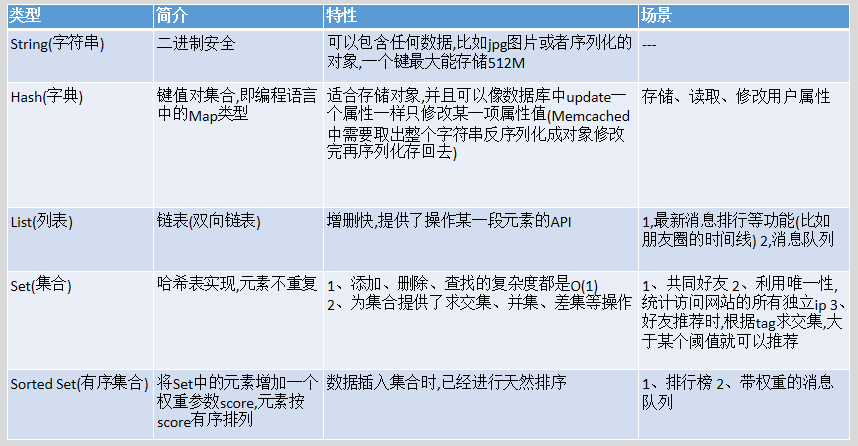
三、Redis的五大常用数据类型(==重要==)
https://github.com/sewenew/redis-plus-plus
1、string数据类型
可以存放任何数据,包括图片。是二进制安全的。
展开代码#设置key值与获取key set key value get key #一次设置多个或者获取多个 mset k1 value1 k2 value2 ... mget k1 k2 ... #获取子串 getrange key start end #start、end是起始与终止的下标 -1代表倒数第一个 #设置子串 setrange key offset newValue #将key的value值从offset位置开始,设置为newValue #设置key的过期时间,以及设置新值 setex key seconds newValue #incr或者incrby只能对value值是数值的情况,进行增加操作,如果value是字符串就不能增加 incr key #每次将key的value值加1 incrby key a #每次将key的value值加a
2、list数据类型
展开代码#在左右两边进行插入 lpush/rpush #在左右两边进行删除 lpop/rpop #遍历 lrange key start end #star与end是起始下标与结束下标 #支持下标(STL中的list是不支持下标的) lindx key index #获取下标为index的值 lset key index value #将下表为index的值设置为value linsert key before/after value newValue #在list的value的前或者后面插入一个新值
3、set数据类型
集合,底层使用的是哈希,元素是唯一的。
展开代码#添加元素 sadd key value1 value2 value3 ... #遍历 smembers key #遍历set中所有元素 #可以在集合中取交集、差集、并集 SINTER/SDIFF/SUNION #随机删除count个元素 spop key count
4、sort set数据类型
zset,会使用double类型分数给每个元素设置权重,然后元素会根据权重进行排序。权重是可以重复的,但是元素是不能重复的。
展开代码#添加元素 zadd key score1 value1 score2 value2 ... #遍历 zrange key start stop [withscores]
5、hash数据类型
map<key1,map< key2, value>>
展开代码#设置与获取 hset key field value hget key field #设置多个与获取多个 hmset key field1 value1 field2 value2 .... hmget key field1 field2 ...
四、redis的配置文件
1、配置文件的路径
展开代码/etc/redis下面,有个文件名 6379.conf
2、杀死redis服务器
展开代码kill -9 进程id号 可以在客户端中直接执行shutdowm命令
3、如何启动redis服务器
展开代码redis-server + 配置文件的路径 sudo redis-server /etc/redis/6379.conf
五、持久化(==重要==)
1、概念
将内存中的数据定期的备份到磁盘中,下一次重启的时候,就可以将磁盘中的数据恢复到内存中。(防止数据丢失了)
2、分类
RDB:将当前数据保存到硬盘(原理是将Reids在内存中的数据库记录定时dump到磁盘上的RDB持久化)
AOF:将每次执行的写命令保存到硬盘(原理是将Reids的操作日志以追加的方式写入文件,类似于MySQL的binlog)
3、RDB持久化
3.1、基本概念
RDB是Redis 默认的持久化方案。==在指定的时间间隔内,执行指定次数的写操作,则会将内存中的数据写入到磁盘中==。即在指定目录下生成一个dump.rdb文件。Redis 重启会通过加载dump.rdb文件恢复数据。(/var/lib/redis/6379)
3.2、触发快照的方式
- 执行shutdown关闭服务器,会触发快照,也就是修改dump.rdb文件的修改时间
- 执行flushall清空数据库,也会触发快照
- 手动执行save或者bgsave可以触发快照,将数据保持到磁盘中
- ==在指定的时间间隔内,执行指定次数的写操作==(==最重要==),自动触发快照
展开代码14:30:40的时候,执行了一次save命令,接着执行两次写操作,等时间达到了14:31:00的时候,文件dump.rdb的修改时间依旧是14:30,但是等时间差达到30s的时候,比如:14:31:10以后再查看dump.rdb会发现该文件的修改时间自动就变为14:31
3.3、优缺点
优点
- 如果对数据的完整性与一致性要求不高,可以使用rdb的持久化方式
- 相对于aof而言,数据的恢复速率是比较快的
缺点
- 进行数据恢复的时候,数据的完整性与一致性不高(可能丢失60s的数据)
- 备份时占用内存,因为Redis 在备份时会独立创建一个fork子进程,将数据写入到一个临时文件(此时内存中的数据是原来的两倍哦),最后再将临时文件替换之前的备份文件
4、AOF持久化
4.1、概念
将所有执行的写命令全部记录下来,然后数据恢复的时候,再将写命令重新执行一次。
4.2、重写
展开代码set k1 100 incr k1 //100 //... 101次 最终k1的值是200 set k1 200 set k1 100 incr k1 300 //... //... del k1
重写之后就可以让文件的大小减小。
触发重写的方式:可以手动执行BGREWRITEAOF命令。
自动触发重写的方式:Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发
展开代码auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb
4.3、优缺点
优点
- 相对于rdb而言,数据的完整性与一致性高。
缺点
- 因为采用的是命令追加的形式,有可能导致文件的体积比较大
- 相对于rdb而言,数据的恢复速率是比较慢的
5、两种持久化的总结
- 如果想要数据恢复快,可以选择rdb持久化;如果想要精度比较高,可以选择aof
- 两种持久化的方式是可以同时存在,起到互补的作用
- 如果单独的以aof持久化的方式,也是可以让服务器启动成功的。
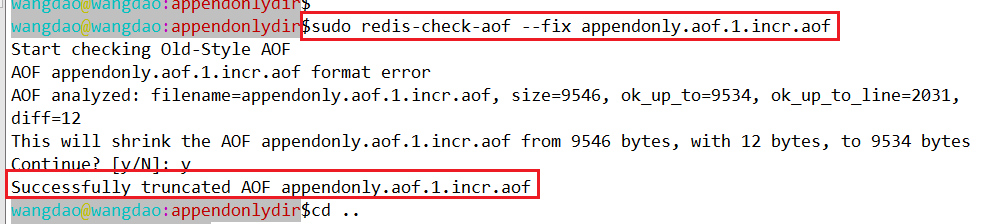
- 如果只有aof持久化方式,并且aof文件被损坏了,redis服务器是启动不成功的。可以使用redis-check-aof文件进行修复
六、Redis的事务
1、概念
一组命令的集合
2、三个阶段
开始事务、命令入队、执行事务
3、事务的命令
展开代码#开始事务 multi #执行事务 exec #取消事务 discard
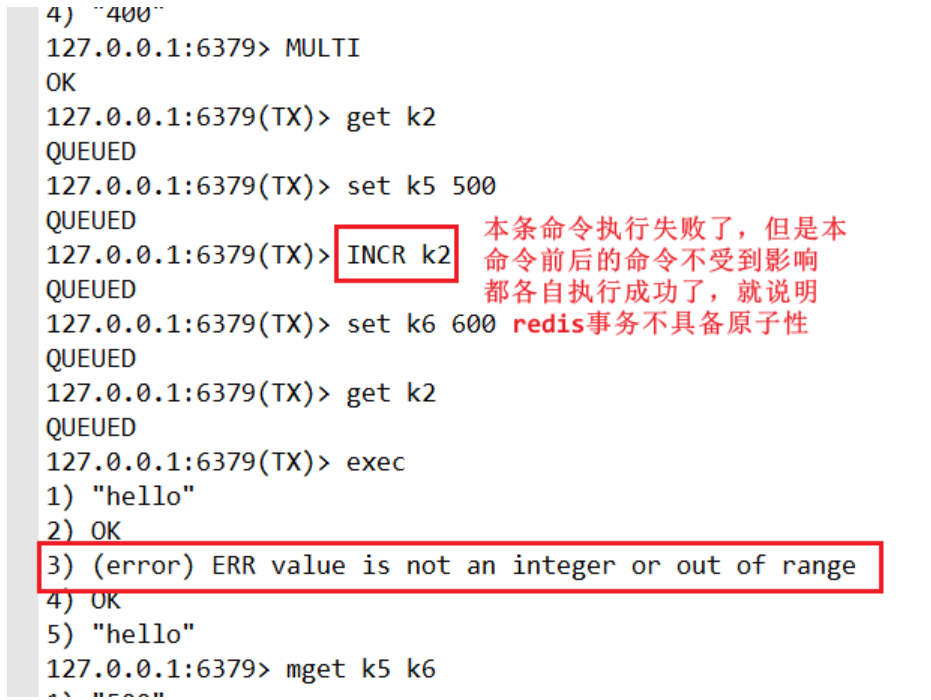

==总结:redis中的事务是没有原子性的。==
4、乐观锁与悲观锁
悲观锁:每次拿数据的时候,都认为其他的线程或者进程会修改数据,所以需要进行加锁。例如:linux学习到的pthread_mutex_t的锁、C++11学习的std::mutex.
乐观锁:每次拿数据的时候,都认为其他的线程或者进程不会修改数据,所以就不需要加锁。实现手段:版本号机制或者CAS机制。
七、主从复制(==比较重要==)
1、概念
主指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点
2、为何要做主从复制
达到负载均衡、防止主机挂掉之后,不能相应请求、读写分离
3、主从复制的配置方法
1、首先进入到/etc/redis下面,将6379.conf拷贝两份,分别取名6380.conf与6381.conf
2、修改6380.conf与6381.conf文件中的以下内容
展开代码port 6380 6381 pidfile "/var/run/redis_6380.pid" "/var/run/redis_6381.pid" logfile "/var/log/redis_6380.log" "/var/log/redis_6381.log" dbfilename "dump6380.rdb" "dump6381.rdb" appendfilename "appendonly6380.aof" "appendonly6381.aof"
3、将三个配置文件进行启动
展开代码sudo redis-server /etc/redis/6379.conf sudo redis-server /etc/redis/6380.conf sudo redis-server /etc/redis/6381.conf

4、分别进入到对应的服务器的客户端下面
展开代码redis-cli -p 6379 redis-cli -p 6380 redis-cli -p 6381
5、查看每台机器的身份信息,发现默认都是主机(他们的role都是master)
展开代码info replication
6、开始配置主从复制的关系,在从机上执行slaveof命令
展开代码#在6380与6381下面执行 slaveof 127.0.0.1 6379 然后查看主从复制的信息info replication,发现从机上可以看到主机的ip、port以及状态信息;在主机上也可以看到从机的ip、port以及状态信息
- 如果从机6381断开了,然后主机6379就不会记录6381的信息了,即使6381重新启动,6379也不会记录6381的信息,因为6381重新启动的时候,是以主机的身份启动的
- 如果主机因为某系愿意挂掉了,那么从机6380与6381会感知到6379的下线,同时会记录主机的状态为down,但是还是会默默的等待主机的上线,当主机6379上线之后,6379依旧会作为主机,然后6380与6381就依旧是6379的从机。
如果主机一直挂掉,永不上线,那么基本的主从复制关系就不能执行写操作,因为没有主机。
八、哨兵模式(==比较==)
哨兵会执行留言协议(造谣)与投票协议(少数服用多数)
配置步骤
1、在/etc/redis下,创建哨兵的配置文件sentinel.conf
展开代码#哨兵 监视 主机名 主机ip 端口 票数 sentinel monitor master6379 127.0.0.1 6379 1
2、启动哨兵的配置文件
展开代码sudo redis-sentinel /etc/redis/sentinel.conf
3、哨兵会监视主机6379的状态变更,如果6379因为某些原因断开,那么哨兵会将自己的一票投递给6380或者6381,谁得到这一票,谁就是新的主机,所以新的主从复制状态就展示出来了。这样就可以解决传统的主从复制,因为主机断掉而不能执行写操作的弊端。
九、面试常见的三个问题(==重要==)
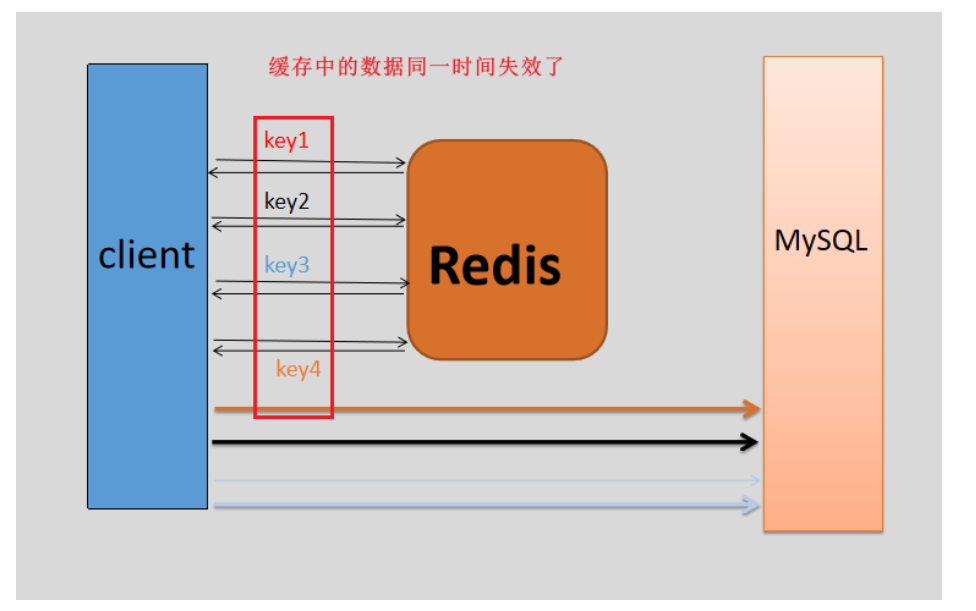
1、缓存雪崩
概念:缓存中的大量数据在同一时间失效了,相当于缓存中没有数据,那么客户端的请求会下沉到底层数据数据库上,那么有可能会导致底层数据库的压力比较大,甚至将底层数据库压垮。
解决问题:1、可以让key值不过期 2、将key的过期失效分散
2、缓存击穿
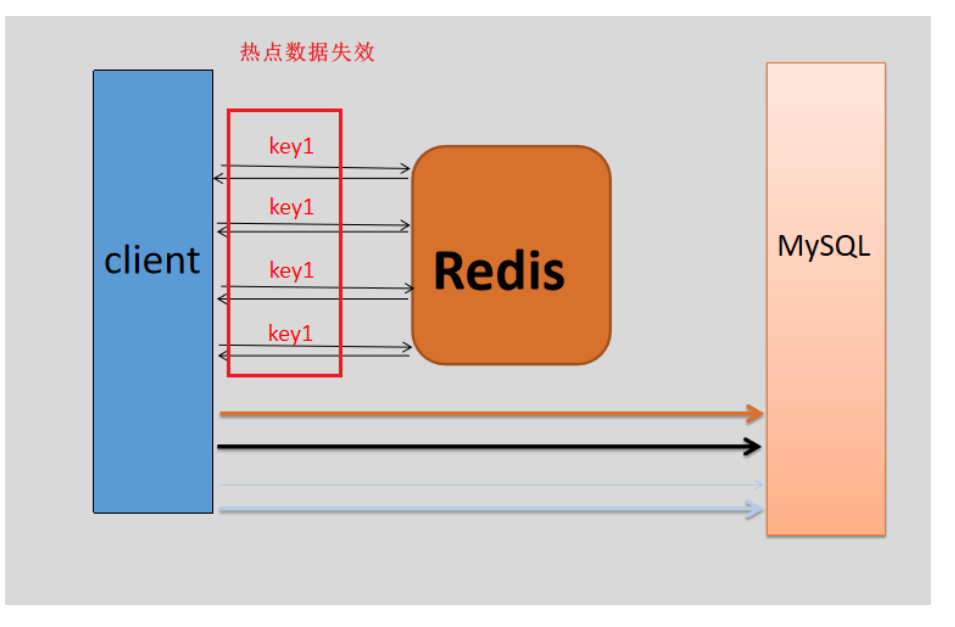
概念:热点数据key在缓存中失效了,热点数据不在缓存中,那么大量客户端的请求会下沉到底层数据数据库上,那么有可能会导致底层数据库的压力比较大,甚至将底层数据库压垮。
解决方案:1、延迟热点数据的失效时间或者不失效 2、可以将数据库看成共享资源,互斥访问数据库
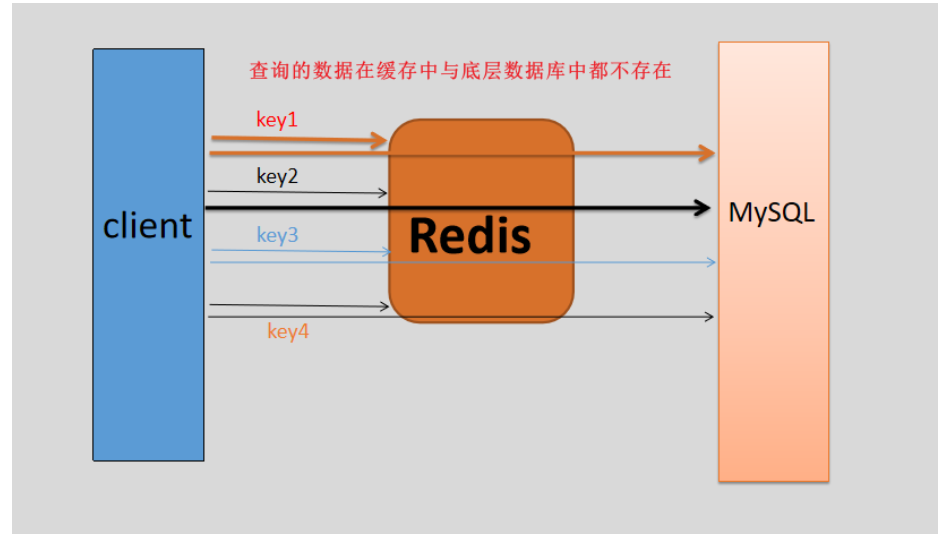
3、缓存穿透
概念:访问的数据在缓存中与底层数据库中都不存在,那么还是会对底层数据库的压力比较大,导致有可能将底层数据库压垮。
解决方案:1、在缓存中设置键值对形式<key, null>
本文作者:冬月
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!